
浅尝 AI 大模型基础(二):CNN与RNN
CNN
全连接层
思绪可以拉回到以前的知识
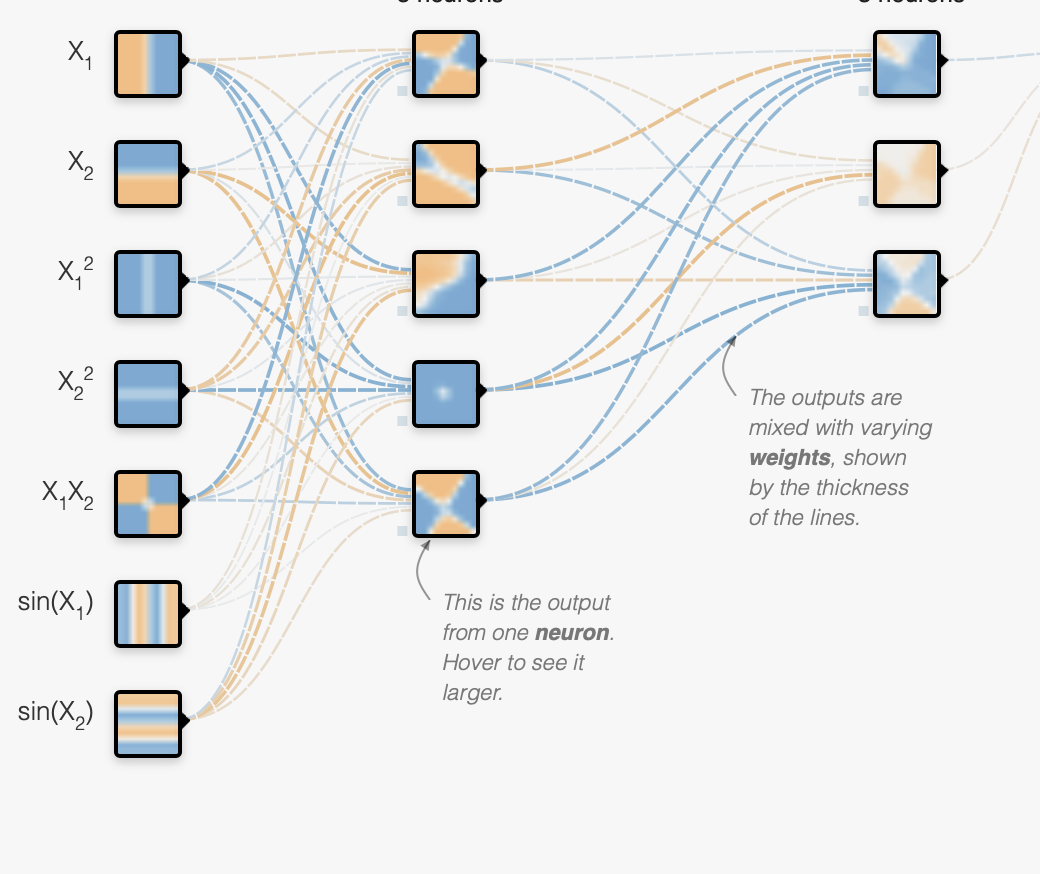
我们之前讲的神经网络,是这样的,可以发现每一个节点都和前一层的所有节点相连接,这种叫全连接层。
但是全连接层有个显而易见的特点,例如:
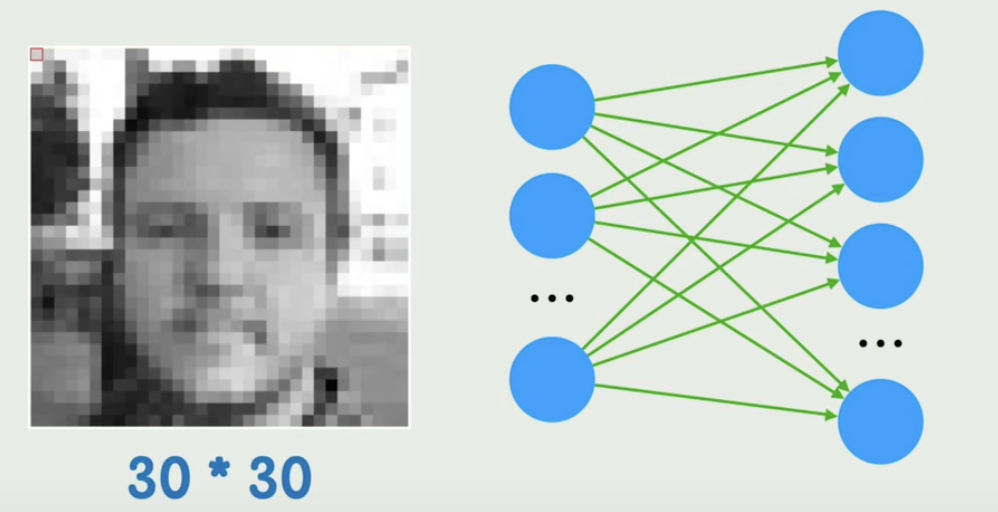
我们的输入是个30*30的灰度图,那给输入层的就是900个神经元,假如下一层的神经元数量是1000个,那么这个全连接层的总参数就是90万个。并且这还只是把图像平铺开,不包含每个像素之间的位置关系,如果图片稍稍平移或改变一些局部信息,但所有的神经元都会和之前不一样,这就是不能很好的理解图像的局部模式。
如何解决这种情况?
卷积计算
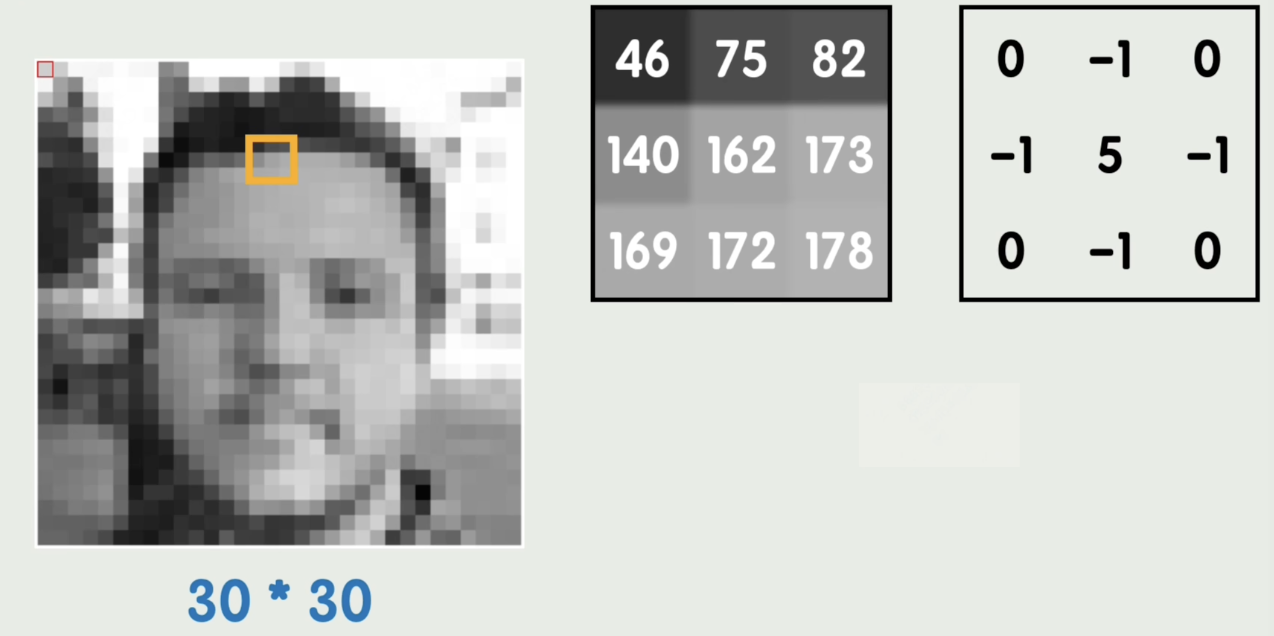
我们在图像中去一个3×3的块,将他的灰度值与另一个矩阵做运算(对应位置相乘,最后求和),遍历整张图片的所有位置,得出的数值形成一个新的图像,这种方式就叫做卷积运算。刚刚给出的矩阵就叫做卷积核。
卷积核早就被应用于传统图像处理领域,不同的卷积核可以达到不同的处理效果(轮廓、锐化、模糊)。但区别在于,图像处理中的卷积核是已知的,神经网络中我们用到的卷积核是未知的,他同样由参数构成。
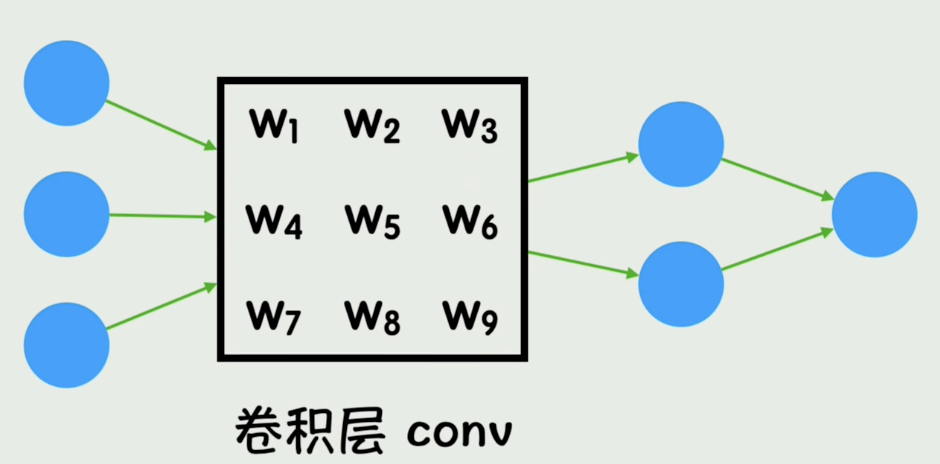 回到经典的神经网络结构,其实就是把一个全连接层替换为了卷积层,不仅能减少参数的数量,还能更有效的捕捉到图像中的局部信息。
回到经典的神经网络结构,其实就是把一个全连接层替换为了卷积层,不仅能减少参数的数量,还能更有效的捕捉到图像中的局部信息。
卷积神经网络CNN
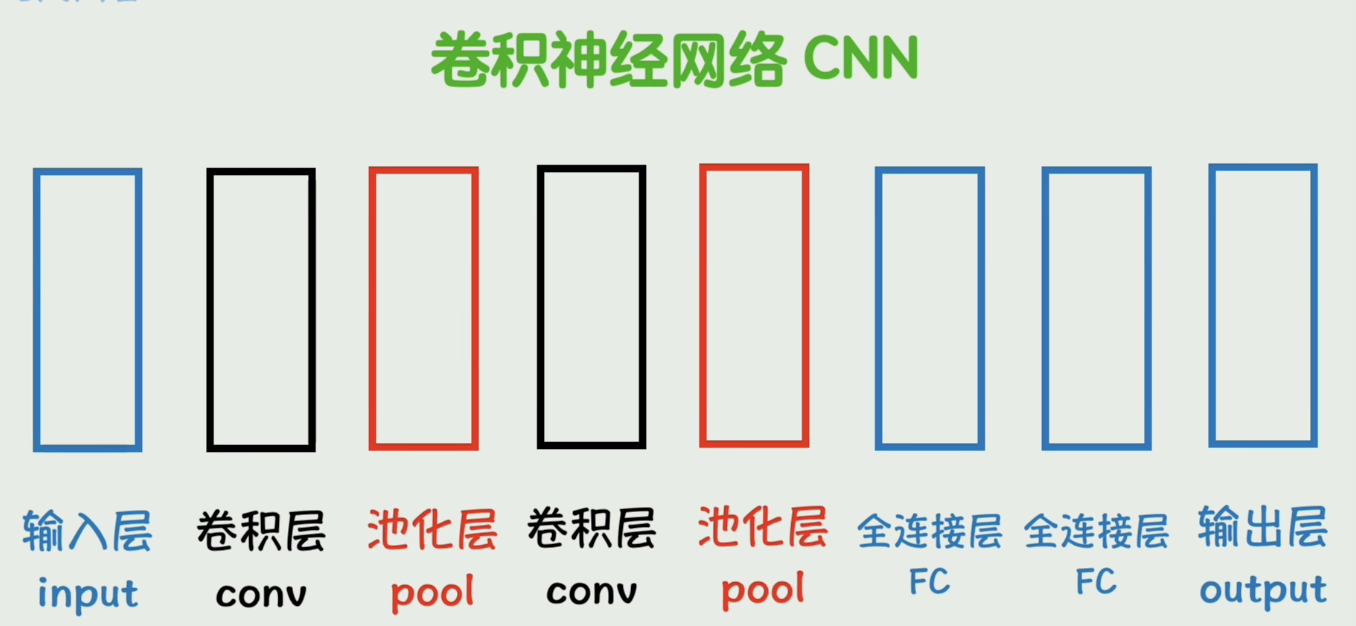
我们可以把原来的小球抽象成这样更直观的样子,可以看到多出来一个池化层,池化层的作用是降低维度的同时保留主要特征,减少计算量。图中的卷积层、池化层、全连接层都可以有多个,而这种适用于图像识别领域的神经网络结构就叫做卷积神经网络
小结
直接看文字依旧比较抽象,但是脑袋里大概可以有一个初步的概念。在小结这里我会将各个地方再说明一下。
灰度值
首先是关于图像变成数据这一部分,也比较好理解,就是用灰度值,彩色的就是RGB。灰度值是什么呢?比如有一张图片,只有中心一个白点,其他地方全是黑色那么抽象成灰度值就是
1 | 0 0 0 |
卷积
为什么可以通过卷积计算的这种方式来识别图片呢,怎么从一堆数字来判断图片是什么呢?
现在我们假设是想识别一只猫。那么CNN是如何识别的呢?
1 | 第一层:边缘 / 线条 |
可以发现,相对与其是说认出什么,不如说是一步一步的提取特征。比如是识别边缘
现在有一块区域用灰度图表示是:
左边数字小 暗,右边数字大 亮
现在用经典的垂直边缘检测核检验
进行卷积运算。不是矩阵乘法,卷积运算是对应位置相乘最后加在一块
1 | 左列:10 × (-1) → -10 |
输出570非常大也就是非常明显的边界
更直观的解释就是
1 | 左边 中间 右边 |
没有边缘就是这样
1 | 10 10 10 |
那这个卷积核是我们已知的,但是真正的神经网络中这个卷积核是未知的,那就像这种检测边缘的卷积核是如何训练出来的呢?
训练过程是这样的
1 | 输入图片 → 卷积核提特征 → 得到结果 → 计算误差 → 反向调整卷积核 |
一开始只是随机数字矩阵比如这样随机的3X3卷积核
1 | [ 0.2 -0.5 1.0 |
这个完全是乱的,没有任何意义。然后用这个核去卷积图片,得到一个特征图,但是此时这个特征图基本上是毫无意义的,因为是模型瞎猜的。
再后面就是开始计算误差,比如经过这一轮的计算,得到一个输出是0.3,而图片的真实值为1。那就可以计算出误差了。然后就根据机器学习的原理,进行反向传播,梯度下降更新卷积核参数。经过非常多次的
1 | 卷积计算 |
最终得到一个合适的卷积核。一张图片会有多个卷积核提取不同特征,每个卷积核负责学习一种特征模式。
池化层
通常在连续的卷积层之间会周期性地插入一个池化层(也称“汇聚”层)。它的作用是逐渐降低数据体的空间尺寸,这样的话就能减少网络中参数的数量,使得计算资源耗费变少,也能有效控制过拟合。池化这个操作比较简单,一般在上采样和下采样的时候用到,没有参数,不可学习。普通池化操作常见的有最大池化(Max Pooling)和平均池化(Mean Pooling)。 其中,最常用的是最大池化。
池化层的降维操作是什么意思呢?
拿最大池化举例:
假设已经提取出特征了,
1 | 1 3 2 4 |
比如数值越大越像“猫”, 6、7、8 → 猫的关键区域
猫原来在左边:
1 | [猫 0 0] |
往右移:
1 | [0 猫 0] |
进行2X2的最大池化计算就是
1 | 原图池化 |
卷积不一样,但是池化后是类似的,关键特征被保留了下来,这样也减少了过拟合的几率。而降维体现在,原来的参数是4 × 4 = 16个数,而现在2 × 2 = 4个数。
那这整个流程就很清晰了,一张图片本质上可以表示为一个矩阵(灰度图为二维矩阵,RGB为三维矩阵)。卷积神经网络通过多个卷积核在图像上滑动,对局部区域(如 3×3)进行加权计算,从而提取图像的特征(如边缘、纹理等)。卷积核在初始时是随机生成的,但会在训练过程中通过反向传播不断优化。卷积层之后通常会接池化层(如最大池化),对局部区域进行降采样,例如将 2×2 区域压缩为 1 个值,从而降低特征图的空间尺寸(如从 4×4 变为 2×2),减少计算量,同时增强模型对位置偏移的鲁棒性。经过多层卷积和池化后,得到高层特征表示,随后通过全连接层将这些特征映射为最终输出(如分类概率)。模型输出的预测值会与真实标签计算损失函数(如交叉熵),然后通过反向传播算法计算梯度,并更新卷积核和其他参数,使损失不断减小。当损失函数收敛时,说明模型学习到了较优的特征提取方式。多个卷积核可以学习不同的特征,从而共同完成对图像的识别任务。
学大模型,使用大模型,让AI给我生成了个简易的demo可以帮助理解这个过程。
因为是浅尝,所以并不是用纯代码解释,这种更利于理解
这里的ReLU就是个激活函数,ReLU 通过将负值置零,引入非线性并过滤无效特征,使神经网络能够学习复杂模式,同时提升计算效率。就是只关注像猫的地方。
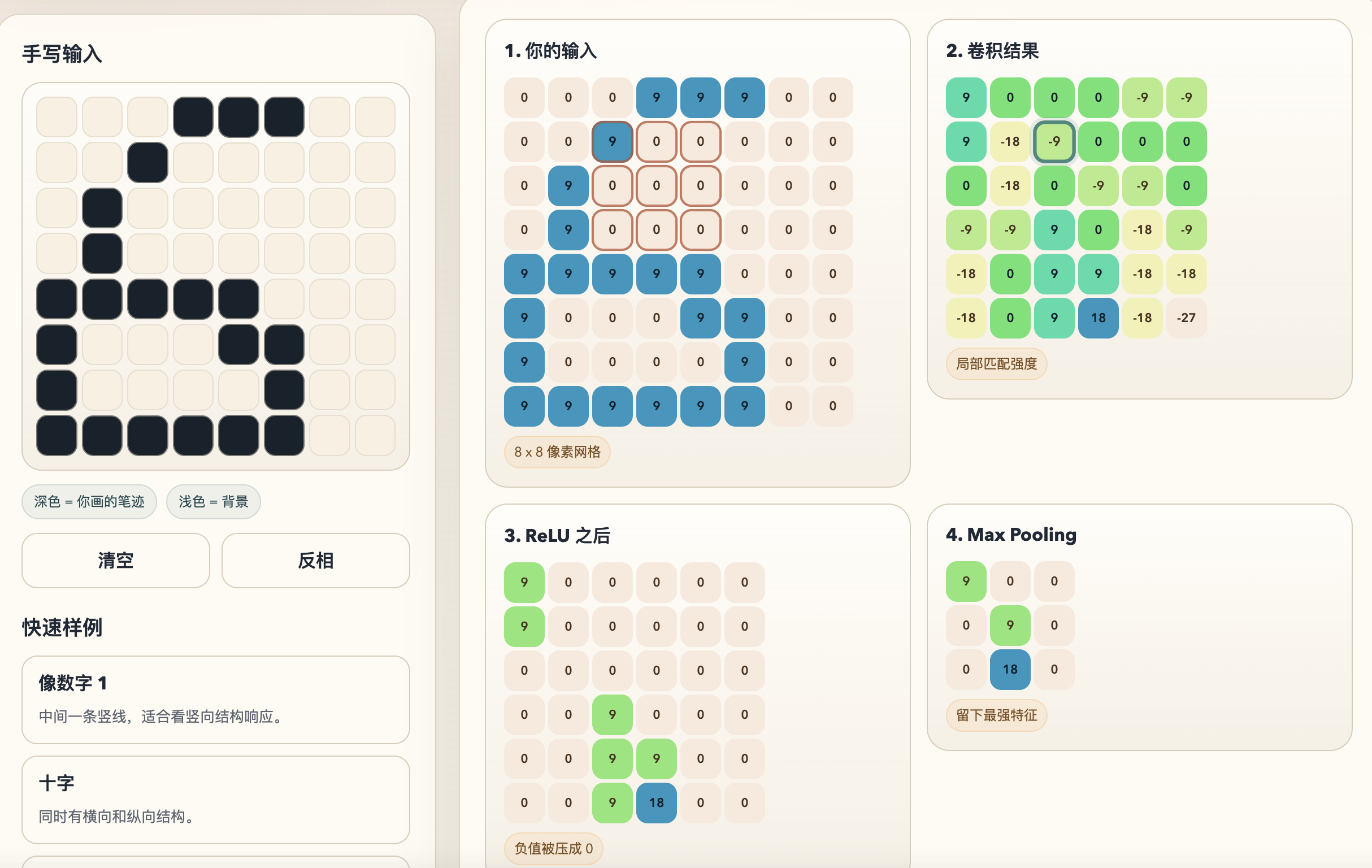
基于识别数字生成的demo,可以观察各个过程
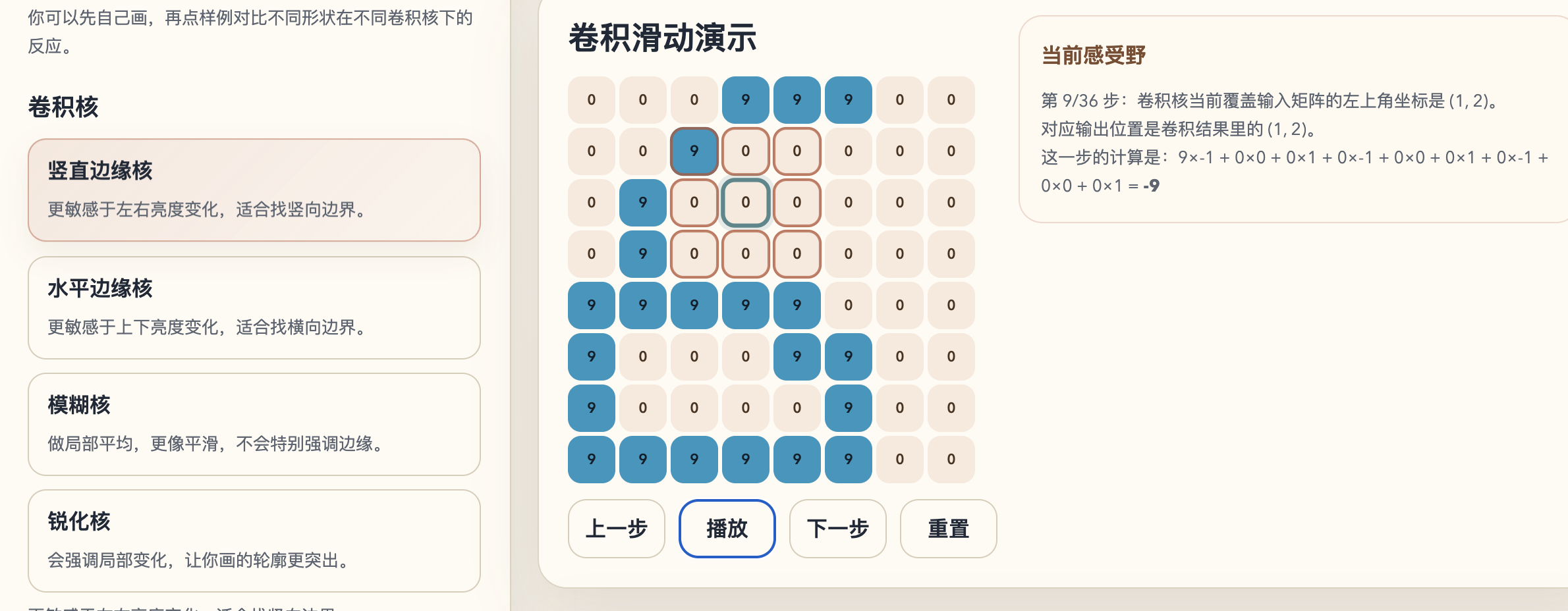
这里面的训练数据是,先在页面脚本里手写了 0-9 的 8 x 8 数字模板,再基于这些模板随机生成一些变体。变体方式主要是轻微平移、少量噪声、局部加粗,最后用这些合成样本训练页面里的那个轻量分类器。
所以更适合识别直接在画板上画出的数字,直接上传图片因为训练数据比较少所以识别率不大

项目地址放这了
https://github.com/Nbccccc/CNN-Handwriting-and-Number-Recognition-Demo
在网上其实也有很多CNN可视化的在线网站
RNN
上面讲到的CNN其实有个很明显的局限性,就是只能处理静态的数据,需要输入定长的特征,比如输入层的单元个数是100个,那么送入模型的特征就必须是100个,增加输入信息,是很难处理的。CNN一般来说比较善于处理2维的图片数据,抽象并概括出图像的隐含特征。但是现实世界中会有很多随时间变化的量,比如一年的气温变化,比如人体的生理信号,比如陀螺仪输出的数据,这些数据属于时序数据,时序数据的最大特点是时间相关性,数据之间前后有关联,所以我们就希望有一种模型能够兼顾(记忆)过往数据的特征,这就用到了RNN。
如何处理文字信息
我们就拿文字信息举例,文字是变长,比如一句话任何一个字的位置不同可能表达的意思都不一样。
按照思路来,我们如何拿数据表达文字呢?可以编码,简单粗暴的方法就是每一个文字或词组都用一个数字来代表,建一个非常大的映射关系表。
但这样有几个显而易见的缺点,第一,只用一个数字表示,不仅要建的表很大,维度也很低(只有一维),第二,数字和数字之间无法表示字与字、词与词之间的联系。为了解决维度低的问题,有人提出了one-hot编码,即准备一个维度非常高的向量,每个字只有向量中一个位置是1,其余全是0。虽然维度低的问题被解决了,但是维度好像又太高了,并且依然没有解决之前的第二个问题。
往后还有词嵌入等方法的探索,到这就不继续往下说了,因为发现再怎么表示也是很难体现字与字或词与词之间的先后关系。那么神经网络中是如何处理这个问题的呢?
RNN循环神经网络
我们现在用开始的神经网络,进行一个词一个词的输入
1 | 你 -> X_1 = g(WX_1+b) -> Y_1 |
可以发现,第二个词的计算过程并没有跟第一个词产生任何关系。但是我们又想让它们直接有关系怎么办呢?
整一个中间人。可以在输出之前,先输出一个隐藏状态h,然后再输出Y
就像这样
1 | 你 -> X_1 = g(W_xh·X_1+b_h) |
这里的各个参数可以
- x_t:当前时刻的输入
- h_{t-1}:上一时刻的记忆
- h_t:当前时刻的记忆
- W_hh:以前的记忆对当前记忆的权重(以前记忆的影响)
- W_xh:输入到记忆的权重(新内容怎么影响记忆)
- W_hy:记忆到输出的权重(输出)
这样前面一个词的信息传递到下一个词那里,这样一直循环下去直到最后一个词,简化一下就是如图
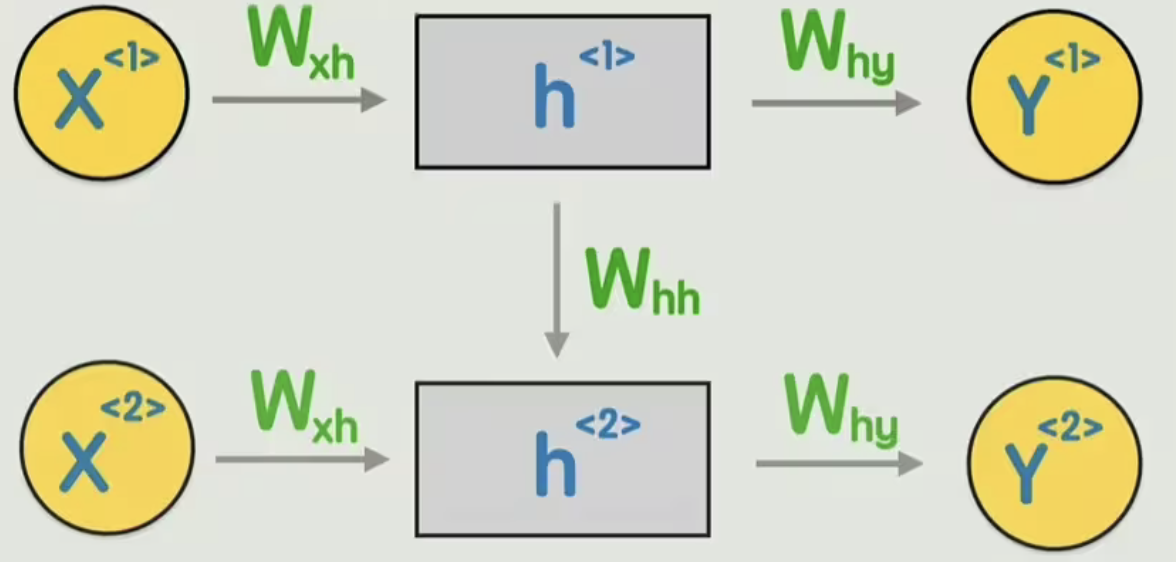
这就是RNN循环神经网络
这个RNN模型就具备了理解词与词之间先后顺序的能力,可以判断一句话中各个单词的褒贬词性,还能给出一句话,不断生成下一个字,以及完成翻译等自然语言处理工作。
但是敏锐的我们一下就发现了,这样好像很容易就梯度爆炸了,因为这样堆积的信息会越来越多,就像我说了“我在中国上学…(中间一大堆)…我住在哪?”,这一套下来直接忘了以前说的啥了,改进的方法也有很多比如LSTM等,但最终的进化形态就是目前近代大模型的依赖Transformer
参考
https://space.bilibili.com/325864133?spm_id_from=333.788.upinfo.head.click
https://blog.csdn.net/Python_cocola/article/details/155521876