
浅尝 AI 大模型基础(三):浅入浅出Transformer
Transformer由论文Attention is All You Need提出,其实论文确实不长并且简单明了

所以其实如果只是为了理解的话,多看个两三遍就能懂这是个怎么样的原理了。
浅入浅出
我们现在假设有个需求:使用神经网络进行翻译工作,翻译这句话"I love you baby" -> “我爱你宝贝”
先用词嵌入的方式把每个词转换成一个词向量,如果直接使用全连接神经网络进行,那每个词都没有上下文信息
假设使用RNN来的话,发现面临串行计算的问题。并且,如果句子太长,也会导致长期依赖困难的问题
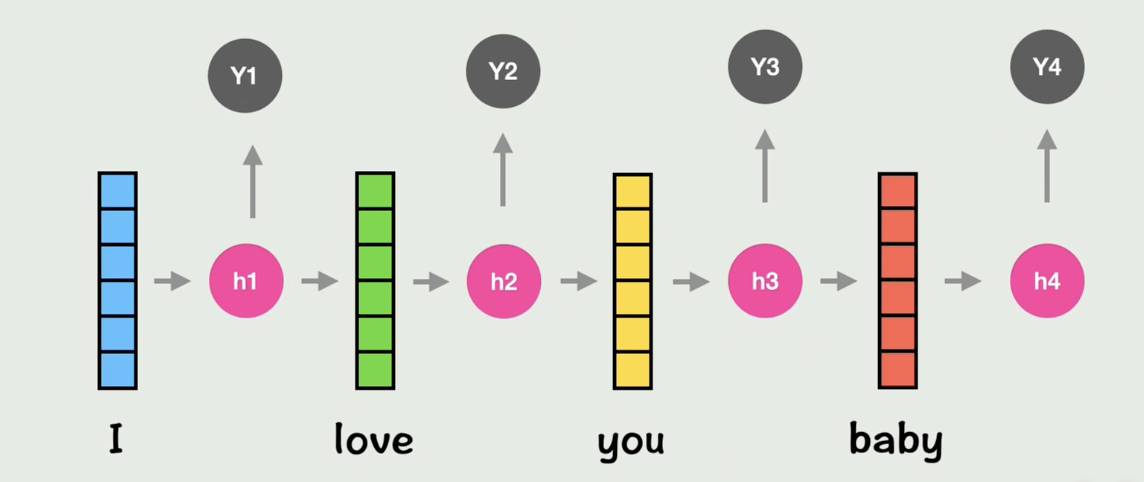
那么如何解决这个问题,就想到了新的一种解决方案(这里我大部分用的是博主视频里的内容,因为真的很清楚了,后面总结我将会用自己的理解再叙述一遍)
首先,为了让输入包含每个词之间的位置信息(前后顺序等),给每个词一个位置编码,表示这个词在整个句子中出现的位置,把这个位置编码加到原来的词向量中,现在这个词就有了位置信息。
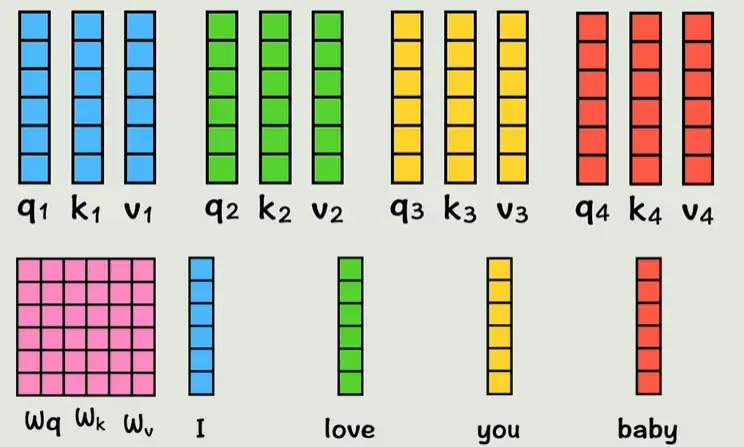
但是现在每个词中还不包括和其他词的关系,注意不到其他词的存在,所以我们用几个新矩阵Wq、Wk、Wv(训练得到)乘上每个词的词向量。当然,在计算机中运算时,是用Wq、Wk、Wv直接乘下方四个词向量拼成的大矩阵,然后直接得到三个矩阵(Q、K、V)。为了方便理解,还是拆分来看。
现在我们的词向量已经通过线性变换映射为了QKV,维度不变,现在我们让q1和k2做点积,代表第一个词和第二个词的相似度,同理类推,得到的系数再与v相乘,最后相加,得到的a1就是包含了全部上下文信息的第一个词的新词向量。
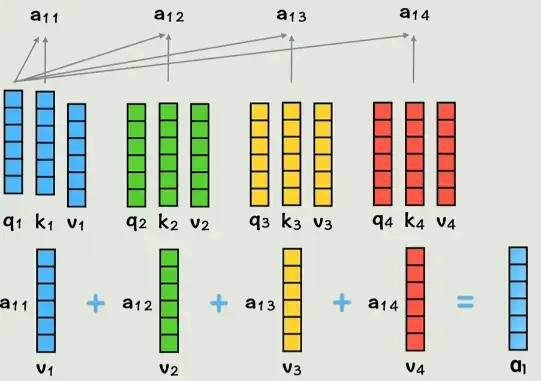
同理,我们得到了所有词的新词向量, 每一个新词向量都包含了所有的上下文信息。这就是注意力机制attention所做的事情。
但是两个词的关系并不是固定的,有时候不同的角度词的意思就是不一样的。对于注意力机制来说,如果只通过一种方式计算一次相关性,灵活性就太低了。所以我们可以增加这个数量,把之前得到的QKV通过两个权重矩阵计算得到两组新的QKV,给每个词两个学习机会,每组QKV称为一个头。再次通过之前的运算得到a向量,拼接起来就得到了和之前一样的结构。我们刚刚的例子有两个头,也属于多头注意力。
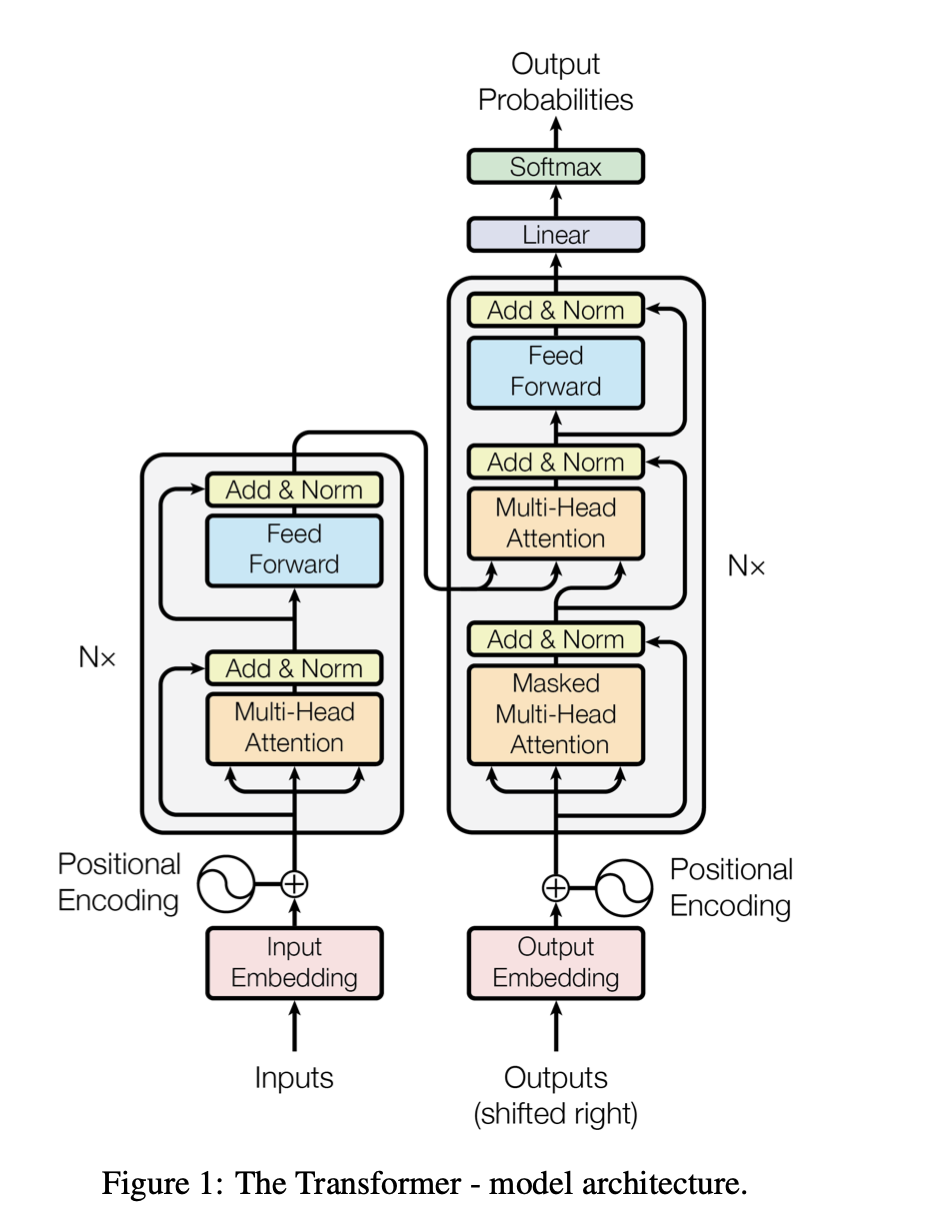
这是论文中的原架构图,上面讲的部分就是多头注意那里(Multi-Head Attention),现在再来介绍一下其他部分
Input Embedding :将词变成词向量,也就是输入
Positional Encoding:这个就是给每个词加上位置编码
Add & Norm(残差连接 + 层归一化):残差的作用是把模块输入直接加回到输出上,避免深层网络训练时信息丢失。归一化是为了把每层输出做标准化,让数值分布更稳定,训练更平滑
Feed Forward:对每个位置上的表示做进一步的非线性变换,是个全连接神经网络,进行一次更深的特征提取
Masked Multi-Head Attention:让 Decoder 在生成当前词时,只能看见前面已经生成的词,不能看后面的词。用来模仿真实推理的效果
Linear:将Decoder当前时刻的隐藏表示,通过一个线性变换映射到词表维度,从而为词表中的每个词生成一个候选得分。
Softmax:将分数转为概率分布。
小结
其实把注意力这点搞清楚,然后再知道这张图,就可以很清晰的懂这个流程了。
还是拿例子来说明。
首先就是模型并不会看英文,只能看懂向量,所以先把每个词转换为词向量
1 | I → 向量1 |
现在光知道有哪些词,也不知道这些词的顺序是怎么样的,所以加个位置编码
1 | I(第1个词) |
现在知道有哪些词了,也知道这些词的顺序了,那怎么让大模型来理解词与词之间的意思呢?这就是Transformer的关键了,注意力机制。比如当翻译到love的时候模型是这样关注的
1 | love 主要关注 I(谁爱) 和 you(爱谁) |
在翻译某个词的过程中会给每个词分配权重,翻译love的时候I和you就会是权重很大,强相关,主语和宾语。这权重怎么算出来的,就是根据那些Wq、Wk、Wv矩阵运算得出的Q、K、V,这些矩阵是训练得到的。而QKV可以理解成
1 | Q(Query)-> 我要找什么 |
上面在讲解的时候也说明了,q会和所有的k进行计算,意义就是“跟谁最相关,就多关注谁。”
到这左边编码器这边就捋顺了,先将词转换为词向量->加上位置编码->计算词与词之间的关联->规整一下(Add & Norm、Feed Forward)->将K、V传到解码器流程里。
而右边解码部分,只需要关注两点:
第一个是Mask那里,就是在翻译的时候盖住后面还没翻译到的,约束它,让它当前时刻只能依赖过去,不能依赖未来,从而模拟真实翻译情况。
第二个,解码与编码交汇的地方,这里解码这里传过去的是Q。然后共同进行“注意力”的计算,这一步也可以叫做Cross Attention(交叉注意力)。这里是让Decoder在生成输出时,可以去关注Encoder对输入句子的理解结果。
比如当前Decoder正在生成“爱”,它会去看Encoder那边哪些输入词最相关:
- 可能重点关注
love - 同时参考
I和you
所以它能实现一种“对齐”:
1 | 我 ←→ I |
当然这不是人工规定的,而是模型通过训练自己学出来的。所以这个模块的作用本质上是:让输出端在生成每个词时,都能回头查看输入句子哪里最相关
这就是翻译能成立的关键。如果没有它,Decoder只能靠前面已经生成的中文继续往下猜,不能真正参考英文原句。
然后剩下的就都一样了,最终给出一个所以词的概率,选出最大的那个。
这其中,编码器的最大作用就是理解句子关系,解码器在一步一步翻译的过程中每一步都在看已生成内容和原始英文句子。这也是为什么是前面神经网络的所不能够的。RNN只能一个词一个词的传,传到后面前面就容易忘了,而Transformer是全局视角全局理解。就像:一个翻译官在看一句话时,不是从左到右死读,而是“每个词都可以随时回头看整句话,找最相关的信息再做决定”
GPT就是训练后只用解码器的部分,也不翻译,就光猜,根据前面的信息猜你想要的,猜着猜着就越猜越准,猜出了你想聊什么,你要什么代码。